First experiences with Amazon Serverless RDS
Amazon have recently released serverless RDS to their line up of cloud based products and I was keen to have a look into how it would work but in doing so I found a few issues...
For those who do not know, RDS is Amazon’s hosted database offering. It stands for “Relational Database Service” and offers cut down versions of SQL, Mysql, Postgres and they have their own “turbo charged” mysql offering called Aurora.
Now, when I say cut down, what I mean by that is that it is a database system that can host various databases formats but with some features missing. For example, if you have a SQL trigger to run a scheduled script you can forget doing that in the actual database as this is not an option.
You will need to look at cloudwatch to trigger a lambda function or something similar.
RDS is not something an on prem DBA could pick up and run with from day one. They would need to relearn how to do a few things.
The other problem with RDS is that it is pricy.
I host a few websites including this blog and each server instance costs around $25 a month and this includes hosting on SSD which decent bandwidth. Most of my hosted services are pretty simple LAMP (Linux Apache, MySQL, PHP) type setups and I did wonder if hosting in AWS would be any cheaper, well the database cost alone shoots that out of the water!
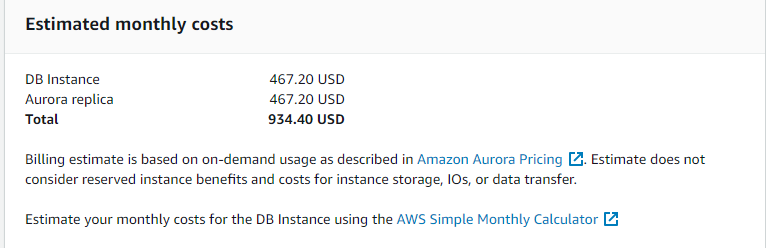
Even if I host it as a non-production database I’m talking $400 plus which is just not worth it or a simple wiki server or the like so when Amazon announced serverless RDS was generally available, I will admit that I got interested, after all, with serverless you only pay for the compute time that you use and my sites will not see that much database traffic.
The way Serverless RDS works is by setting up a “virtual cluster” in your AWS VPC which then automatically maps on to the actual Amazon RDS system. From that virtual cluster it’s possible to connect to the database instance that is generated and create a database just like you would with an on-prem mysql server.
When I first started exploring Serverless RDS in AWS, I attempted in the London region but London does not seem to support serverless RDS. It appears that “generally available” does not mean that it’s available in all regions just that it isn’t BETA any more!
Anyway, a second attempt in Ireland was more successful in that I actually got the option to create a serverless RDS cluster which requires two subnets in different AWS availability zones. Once the cluster is created the next thing to do is to get a database restored into the cluster…. but no, that is not really an option even though there is the “restore from S3” option except that this option is for the more expensive, full blown RDS and even in there it’s a bit weak to say that least. It will simply restore every file in a particular S3 bucket that fits the file filter you provide. You also cannot restore to a different name or do anything remotely clever. It’s a shame, I hope this gets expanded upon.
One way to get into the database was via a site to site VPN that terminates on the Ireland VPC. Serverless RDS cannot host an external IP address and nor should it. No one should need access to a database over the internet. Another option to get to the database would have been to spin up an EC2 machine in the Ireland VPC then allocate a public AWS IP to that VPC. This way I would have then been able to RDP to the server and from there talk to the database.
One thing that did surprise me is that even though I created the security group rules, I was not able to ping my serverless RDS endpoint.
No warning was generated when I added the rule so for a while I was a bit stumped when my VPN was up but my PING to the RDS cluster wasn’t replying. It seems that for quite a few services, AWS do not allow ICMP traffic, even if you have added the necessary security rules.

DB snapshots allow for a few restore, I cannot restore to another name and then do a comparison. I cannot restore to another cluster or rename for say UAT. Restore from snapshot is an instant overwrite-and-destroy-existing-data option.
This might sound like a lot of negatives but it isn’t, once the Serverless is setup and you’ve got a connection to the cluster, it’s quite cool to use and see the variable amount of capacity units that your database requires as it does stuff.
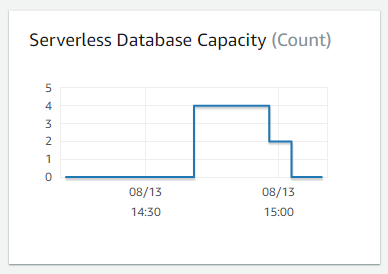
This is a screenshot of my serverless RDS cluster in action. For a while, the cluster is doing nothing so isn’t using any capacity units then I kick off a restore which needs compute power so the capacity units go for 0 to 4 which is the maximum I’ve allowed for that cluster.
Once the restore is complete, the cluster is once again doing nothing so the capacity units scale back, first to 2 then to 0. It will not scale up again until I need it.
This is great because it means that I am only paying for the time that the cluster is actively using CPU cycles. When it isn’t, I’m not paying and yet the cluster and databases are still there.
This is the actual log of the process:
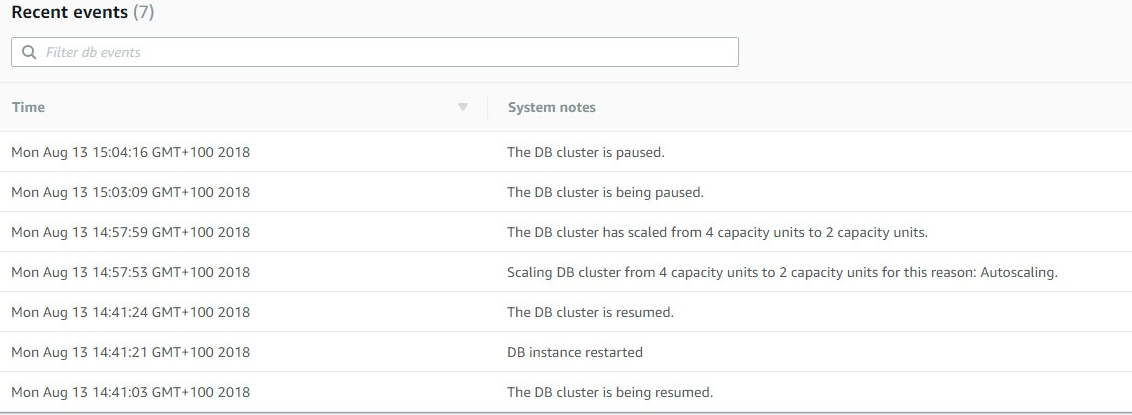
Clearly, you can see the ramp up time which is about 21 seconds then the cool down time as the amount of processor load goes down to the point that the database isn’t required anymore so the server can basically go to sleep.
One small issues that I noticed is that the initial connection is a few seconds too long.
If you’re running a commercial website then you don’t want to wait ten seconds plus just for the database to be fired up. However, for internal, low usage applications then this might be a good, cheaper option than a full blown RDS cluster so it's certainly worth a look.
Subscribe to Ramblings of a Sysadmin
Get the latest posts delivered right to your inbox